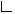 java.lang.String
java.lang.String
|
JavaTM 2 Platform Standard Ed. 6 |
|||||||||
| 上一個類別 下一個類別 | 框架 無框架 | |||||||||
| 摘要: 巢狀 | 欄位 | 建構子 | 方法 | 詳細資訊: 欄位 | 建構子 | 方法 | |||||||||
java.lang.Object
public final class String
String 類別代表字元串。Java 程序中的所有字元串文字值(如 "abc" )都作為此類別的實例實作。
字元串是常數;它們的值在創建之後不能更改。字元串緩衝區支持可變的字元串。因為 String 物件是不可變的,所以可以共享。例如:
String str = "abc";
等效於:
char data[] = {'a', 'b', 'c'};
String str = new String(data);
下面給出了一些如何使用字元串的更多範例:
System.out.println("abc");
String cde = "cde";
System.out.println("abc" + cde);
String c = "abc".substring(2,3);
String d = cde.substring(1, 2);
String 類別包括的方法可用於檢查序列的單個字元、比較字元串、搜尋字元串、提取子字元串、創建字元串副本並將所有字元全部轉換為大寫或小寫。大小寫映射基於 Character 類別指定的 Unicode 標準版。
Java 語言提供對字元串串聯符號("+")以及將其他物件轉換為字元串的特殊支持。字元串串聯是通過 StringBuilder(或 StringBuffer)類別及其 append 方法實作的。字元串轉換是通過 toString 方法實作的,該方法由 Object 類別定義,並可被 Java 中的全部類別繼承。有關字元串串聯和轉換的更多資訊,請參閱 Gosling、Joy 和 Steele 合著的 The Java Language Specification。
除非另行說明,否則將 null 參數傳遞給此類別中的建構子或方法將拋出 NullPointerException。
String 表示一個 UTF-16 格式的字元串,其中的增補字元 由代理項對 表示(有關詳細資訊,請參閱 Character 類別中的 Unicode 字元表示形式)。索引值是指 char 程式碼單元,因此增補字元在 String 中佔用兩個位置。
String 類別提供處理 Unicode 程式碼點(即字元)和 Unicode 程式碼單元(即 char 值)的方法。
Object.toString(),
StringBuffer,
StringBuilder,
Charset,
序列化表格| 欄位摘要 | |
|---|---|
static Comparator<String> |
CASE_INSENSITIVE_ORDER
一個對 String 物件進行排序的 Comparator,作用與 compareToIgnoreCase 相同。 |
| 建構子摘要 | |
|---|---|
String()
初始化一個新創建的 String 物件,使其表示一個空字元序列。 |
|
String(byte[] bytes)
通過使用平臺的預設字元集解碼指定的 byte 陣列,建構一個新的 String。 |
|
String(byte[] bytes,
Charset charset)
通過使用指定的 charset 解碼指定的 byte 陣列,建構一個新的 String。 |
|
String(byte[] ascii,
int hibyte)
已過時。 該方法無法將位元組正確地轉換為字元。從 JDK 1.1 開始,完成該轉換的首選方法是使用帶有 Charset、字元集名稱,或使用平臺預設字元集的 String 建構子。 |
|
String(byte[] bytes,
int offset,
int length)
通過使用平臺的預設字元集解碼指定的 byte 子陣列,建構一個新的 String。 |
|
String(byte[] bytes,
int offset,
int length,
Charset charset)
通過使用指定的 charset 解碼指定的 byte 子陣列,建構一個新的 String。 |
|
String(byte[] ascii,
int hibyte,
int offset,
int count)
已過時。 該方法無法將位元組正確地轉換為字元。從 JDK 1.1 開始,完成該轉換的首選方法是使用帶有 Charset、字元集名稱,或使用平臺預設字元集的 String 建構子。 |
|
String(byte[] bytes,
int offset,
int length,
String charsetName)
通過使用指定的字元集解碼指定的 byte 子陣列,建構一個新的 String。 |
|
String(byte[] bytes,
String charsetName)
通過使用指定的 charset 解碼指定的 byte 陣列,建構一個新的 String。 |
|
String(char[] value)
分派一個新的 String,使其表示字元陣列參數中當前包含的字元序列。 |
|
String(char[] value,
int offset,
int count)
分派一個新的 String,它包含取自字元陣列參數一個子陣列的字元。 |
|
String(int[] codePoints,
int offset,
int count)
分派一個新的 String,它包含 Unicode 程式碼點陣列參數一個子陣列的字元。 |
|
String(String original)
初始化一個新創建的 String 物件,使其表示一個與參數相同的字元序列;換句話說,新創建的字元串是該參數字元串的副本。 |
|
String(StringBuffer buffer)
分派一個新的字元串,它包含字元串緩衝區參數中當前包含的字元序列。 |
|
String(StringBuilder builder)
分派一個新的字元串,它包含字元串產生器參數中當前包含的字元序列。 |
|
| 方法摘要 | |
|---|---|
char |
charAt(int index)
返回指定索引處的 char 值。 |
int |
codePointAt(int index)
返回指定索引處的字元(Unicode 程式碼點)。 |
int |
codePointBefore(int index)
返回指定索引之前的字元(Unicode 程式碼點)。 |
int |
codePointCount(int beginIndex,
int endIndex)
返回此 String 的指定文本範圍中的 Unicode 程式碼點數。 |
int |
compareTo(String anotherString)
按字典順序比較兩個字元串。 |
int |
compareToIgnoreCase(String str)
按字典順序比較兩個字元串,不考慮大小寫。 |
String |
concat(String str)
將指定字元串連接到此字元串的結尾。 |
boolean |
contains(CharSequence s)
當且僅當此字元串包含指定的 char 值序列時,返回 true。 |
boolean |
contentEquals(CharSequence cs)
將此字元串與指定的 CharSequence 比較。 |
boolean |
contentEquals(StringBuffer sb)
將此字元串與指定的 StringBuffer 比較。 |
static String |
copyValueOf(char[] data)
返回指定陣列中表示該字元序列的 String。 |
static String |
copyValueOf(char[] data,
int offset,
int count)
返回指定陣列中表示該字元序列的 String。 |
boolean |
endsWith(String suffix)
測試此字元串是否以指定的後綴結束。 |
boolean |
equals(Object anObject)
將此字元串與指定的物件比較。 |
boolean |
equalsIgnoreCase(String anotherString)
將此 String 與另一個 String 比較,不考慮大小寫。 |
static String |
format(Locale l,
String format,
Object... args)
使用指定的語言環境、格式字元串和參數返回一個格式化字元串。 |
static String |
format(String format,
Object... args)
使用指定的格式字元串和參數返回一個格式化字元串。 |
byte[] |
getBytes()
使用平臺的預設字元集將此 String 編碼為 byte 序列,並將結果存儲到一個新的 byte 陣列中。 |
byte[] |
getBytes(Charset charset)
使用給定的 charset 將此 String 編碼到 byte 序列,並將結果存儲到新的 byte 陣列。 |
void |
getBytes(int srcBegin,
int srcEnd,
byte[] dst,
int dstBegin)
已過時。 該方法無法將字元正確轉換為位元組。從 JDK 1.1 起,完成該轉換的首選方法是通過 getBytes() 方法,該方法使用平臺的預設字元集。 |
byte[] |
getBytes(String charsetName)
使用指定的字元集將此 String 編碼為 byte 序列,並將結果存儲到一個新的 byte 陣列中。 |
void |
getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
將字元從此字元串複製到目標字元陣列。 |
int |
hashCode()
返回此字元串的雜湊碼。 |
int |
indexOf(int ch)
返回指定字元在此字元串中第一次出現處的索引。 |
int |
indexOf(int ch,
int fromIndex)
返回在此字元串中第一次出現指定字元處的索引,從指定的索引開始搜尋。 |
int |
indexOf(String str)
返回指定子字元串在此字元串中第一次出現處的索引。 |
int |
indexOf(String str,
int fromIndex)
返回指定子字元串在此字元串中第一次出現處的索引,從指定的索引開始。 |
String |
intern()
返回字元串物件的規範化表示形式。 |
boolean |
isEmpty()
當且僅當 length() 為 0 時返回 true。 |
int |
lastIndexOf(int ch)
返回指定字元在此字元串中最後一次出現處的索引。 |
int |
lastIndexOf(int ch,
int fromIndex)
返回指定字元在此字元串中最後一次出現處的索引,從指定的索引處開始進行反向搜尋。 |
int |
lastIndexOf(String str)
返回指定子字元串在此字元串中最右邊出現處的索引。 |
int |
lastIndexOf(String str,
int fromIndex)
返回指定子字元串在此字元串中最後一次出現處的索引,從指定的索引開始反向搜尋。 |
int |
length()
返回此字元串的長度。 |
boolean |
matches(String regex)
告知此字元串是否比對給定的正則表達式。 |
int |
offsetByCodePoints(int index,
int codePointOffset)
返回此 String 中從給定的 index 處偏移 codePointOffset 個程式碼點的索引。 |
boolean |
regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
測試兩個字元串區域是否相等。 |
boolean |
regionMatches(int toffset,
String other,
int ooffset,
int len)
測試兩個字元串區域是否相等。 |
String |
replace(char oldChar,
char newChar)
返回一個新的字元串,它是通過用 newChar 替換此字元串中出現的所有 oldChar 得到的。 |
String |
replace(CharSequence target,
CharSequence replacement)
使用指定的文字值替換序列替換此字元串所有比對文字值目標序列的子字元串。 |
String |
replaceAll(String regex,
String replacement)
使用給定的 replacement 替換此字元串所有比對給定的正則表達式的子字元串。 |
String |
replaceFirst(String regex,
String replacement)
使用給定的 replacement 替換此字元串比對給定的正則表達式的第一個子字元串。 |
String[] |
split(String regex)
根據給定正則表達式的比對拆分此字元串。 |
String[] |
split(String regex,
int limit)
根據比對給定的正則表達式來拆分此字元串。 |
boolean |
startsWith(String prefix)
測試此字元串是否以指定的前綴開始。 |
boolean |
startsWith(String prefix,
int toffset)
測試此字元串從指定索引開始的子字元串是否以指定前綴開始。 |
CharSequence |
subSequence(int beginIndex,
int endIndex)
返回一個新的字元序列,它是此序列的一個子序列。 |
String |
substring(int beginIndex)
返回一個新的字元串,它是此字元串的一個子字元串。 |
String |
substring(int beginIndex,
int endIndex)
返回一個新字元串,它是此字元串的一個子字元串。 |
char[] |
toCharArray()
將此字元串轉換為一個新的字元陣列。 |
String |
toLowerCase()
使用預設語言環境的規則將此 String 中的所有字元都轉換為小寫。 |
String |
toLowerCase(Locale locale)
使用給定 Locale 的規則將此 String 中的所有字元都轉換為小寫。 |
String |
toString()
返回此物件本身(它已經是一個字元串!)。 |
String |
toUpperCase()
使用預設語言環境的規則將此 String 中的所有字元都轉換為大寫。 |
String |
toUpperCase(Locale locale)
使用給定 Locale 的規則將此 String 中的所有字元都轉換為大寫。 |
String |
trim()
返回字元串的副本,忽略前導空白和尾部空白。 |
static String |
valueOf(boolean b)
返回 boolean 參數的字元串表示形式。 |
static String |
valueOf(char c)
返回 char 參數的字元串表示形式。 |
static String |
valueOf(char[] data)
返回 char 陣列參數的字元串表示形式。 |
static String |
valueOf(char[] data,
int offset,
int count)
返回 char 陣列參數的特定子陣列的字元串表示形式。 |
static String |
valueOf(double d)
返回 double 參數的字元串表示形式。 |
static String |
valueOf(float f)
返回 float 參數的字元串表示形式。 |
static String |
valueOf(int i)
返回 int 參數的字元串表示形式。 |
static String |
valueOf(long l)
返回 long 參數的字元串表示形式。 |
static String |
valueOf(Object obj)
返回 Object 參數的字元串表示形式。 |
| 從類別 java.lang.Object 繼承的方法 |
|---|
clone, finalize, getClass, notify, notifyAll, wait, wait, wait |
| 欄位詳細資訊 |
|---|
public static final Comparator<String> CASE_INSENSITIVE_ORDER
String 物件進行排序的 Comparator,作用與 compareToIgnoreCase 相同。此比較器是可序列化的。
注意,Comparator 不 考慮語言環境,因此可能導致在某些語言環境中的排序效果不理想。java.text 套件提供 Collator 完成與語言環境有關的排序。
Collator.compare(String, String)| 建構子詳細資訊 |
|---|
public String()
String 物件,使其表示一個空字元序列。注意,由於 String 是不可變的,所以無需使用此建構子。
public String(String original)
String 物件,使其表示一個與參數相同的字元序列;換句話說,新創建的字元串是該參數字元串的副本。由於 String 是不可變的,所以無需使用此建構子,除非需要 original 的顯式副本。
original - 一個 String。public String(char[] value)
String,使其表示字元陣列參數中當前包含的字元序列。該字元陣列的內容已被複製;後續對字元陣列的修改不會影響新創建的字元串。
value - 字元串的初始值
public String(char[] value,
int offset,
int count)
String,它包含取自字元陣列參數一個子陣列的字元。offset 參數是子陣列第一個字元的索引,count 參數指定子陣列的長度。該子陣列的內容已被複製;後續對字元陣列的修改不會影響新創建的字元串。
value - 作為字元源的陣列。offset - 初始偏移量。count - 長度。
IndexOutOfBoundsException - 如果 offset 和 count 參數索引字元超出 value 陣列的範圍。
public String(int[] codePoints,
int offset,
int count)
String,它包含 Unicode 程式碼點陣列參數一個子陣列的字元。offset 參數是該子陣列第一個程式碼點的索引,count 參數指定子陣列的長度。將該子陣列的內容轉換為 char;後續對 int 陣列的修改不會影響新創建的字元串。
codePoints - 作為 Unicode 程式碼點的源的陣列。offset - 初始偏移量。count - 長度。
IllegalArgumentException - 如果在 codePoints 中發現任何無效的 Unicode 程式碼點
IndexOutOfBoundsException - 如果 offset 和 count 參數索引字元超出 codePoints 陣列的範圍。
@Deprecated
public String(byte[] ascii,
int hibyte,
int offset,
int count)
Charset、字元集名稱,或使用平臺預設字元集的 String 建構子。
String,它是根據一個 8 位整數值陣列的子陣列建構的。
offset 參數是該子陣列的第一個 byte 的索引,count 參數指定子陣列的長度。
子陣列中的每個 byte 都按照上述方法轉換為 char。
ascii - 要轉換為字元的 byte。hibyte - 每個 16 位 Unicode 程式碼單元的前 8 位。offset - 初始偏移量。count - 長度。
IndexOutOfBoundsException - 如果 offset 或 count 參數無效。String(byte[], int),
String(byte[], int, int, java.lang.String),
String(byte[], int, int, java.nio.charset.Charset),
String(byte[], int, int),
String(byte[], java.lang.String),
String(byte[], java.nio.charset.Charset),
String(byte[])
@Deprecated
public String(byte[] ascii,
int hibyte)
Charset、字元集名稱,或使用平臺預設字元集的 String 建構子。
String,它包含根據一個 8 位整數值陣列建構的字元。所得字元串中的每個字元 c 都是根據 byte 陣列中的相應元件 b 建構的,如下所示:
c == (char)(((hibyte & 0xff) << 8)
| (b & 0xff))
ascii - 要轉換為字元的 byte。hibyte - 每個 16 位 Unicode 程式碼單元的前 8 位。String(byte[], int, int, java.lang.String),
String(byte[], int, int, java.nio.charset.Charset),
String(byte[], int, int),
String(byte[], java.lang.String),
String(byte[], java.nio.charset.Charset),
String(byte[])
public String(byte[] bytes,
int offset,
int length,
String charsetName)
throws UnsupportedEncodingException
String。新 String 的長度是一個字元集函數,因此可能不等於子陣列的長度。
當給定 byte 在給定字元集中無效的情況下,此建構子的行為沒有指定。如果需要對解碼過程進行更多控制,則應該使用 CharsetDecoder 類別。
bytes - 要解碼為字元的 byteoffset - 要解碼的第一個 byte 的索引length - 要解碼的 byte 數charsetName - 受支持 charset 的名稱
UnsupportedEncodingException - 如果指定的字元集不受支持
IndexOutOfBoundsException - 如果 offset 和 length 參數索引字元超出 bytes 陣列的範圍
public String(byte[] bytes,
int offset,
int length,
Charset charset)
String。新 String 的長度是字元集的函數,因此可能不等於子陣列的長度。
此方法總是使用此字元集的預設替代字元串替代錯誤輸入 (malformed-input) 和不可映射字元 (unmappable-character) 序列。如果需要對解碼過程進行更多控制,則應該使用 CharsetDecoder 類別。
bytes - 要解碼為字元的 byteoffset - 要解碼的第一個 byte 的索引length - 要解碼的 byte 數charset - 用來解碼 bytes 的 charset
IndexOutOfBoundsException - 如果 offset 和 length 參數索引字元超出 bytes 陣列的邊界
public String(byte[] bytes,
String charsetName)
throws UnsupportedEncodingException
String。新 String 的長度是字元集的函數,因此可能不等於 byte 陣列的長度。
當給定 byte 在給定字元集中無效的情況下,此建構子的行為沒有指定。如果需要對解碼過程進行更多控制,則應該使用 CharsetDecoder 類別。
bytes - 要解碼為字元的 bytecharsetName - 受支持的 charset 的名稱
UnsupportedEncodingException - 如果指定字元集不受支持
public String(byte[] bytes,
Charset charset)
String。新 String 的長度是字元集的函數,因此可能不等於 byte 陣列的長度。
此方法總是使用此字元集的預設替代字元串替代錯誤輸入和不可映射字元序列。如果需要對解碼過程進行更多控制,則應該使用 CharsetDecoder 類別。
bytes - 要解碼為字元的 bytecharset - 要用來解碼 bytes 的 charset
public String(byte[] bytes,
int offset,
int length)
String。新 String 的長度是字元集的函數,因此可能不等於該子陣列的長度。
當給定 byte 在給定字元集中無效的情況下,此建構子的行為沒有指定。如果需要對解碼過程進行更多控制,則應該使用 CharsetDecoder 類別。
bytes - 要解碼為字元的 byteoffset - 要解碼的第一個 byte 的索引length - 要解碼的 byte 數
IndexOutOfBoundsException - 如果 offset 和 length 參數索引字元超出 bytes 陣列的範圍public String(byte[] bytes)
String。新 String 的長度是字元集的函數,因此可能不等於 byte 陣列的長度。
當給定 byte 在給定字元集中無效的情況下,此建構子的行為沒有指定。如果需要對解碼過程進行更多控制,則應該使用 CharsetDecoder 類別。
bytes - 要解碼為字元的 bytepublic String(StringBuffer buffer)
buffer - 一個 StringBufferpublic String(StringBuilder builder)
提供此建構子是為了簡化到 StringBuilder 的遷移。通過 toString 方法從字元串產生器中獲取字元串可能運行的更快,因此通常作為首選。
builder - 一個 StringBuilder| 方法詳細資訊 |
|---|
public int length()
CharSequence 中的 lengthpublic boolean isEmpty()
length() 為 0 時返回 true。
length() 為 0,則返回 true;否則返回 false。public char charAt(int index)
char 值。索引範圍為從 0 到 length() - 1。序列的第一個 char 值位於索引 0 處,第二個位於索引 1 處,依此類別推,這類似於陣列索引。
如果索引指定的 char 值是代理項,則返回代理項值。
CharSequence 中的 charAtindex - char 值的索引。
char 值。第一個 char 值位於索引 0 處。
IndexOutOfBoundsException - 如果 index 參數為負或小於此字元串的長度。public int codePointAt(int index)
char 值(Unicode 程式碼單元),其範圍從 0 到 length() - 1。
如果給定索引指定的 char 值屬於高代理項範圍,則後續索引小於此 String 的長度;如果後續索引處的 char 值屬於低代理項範圍,則返回該代理項對相應的增補程式碼點。否則,返回給定索引處的 char 值。
index - char 值的索引
index 處字元的程式碼點值
IndexOutOfBoundsException - 如果 index 參數為負或小於此字元串的長度。public int codePointBefore(int index)
char 值(Unicode 程式碼單元),其範圍從 1 到 length。
如果 (index - 1) 處的 char 值屬於低代理項範圍,則 (index - 2) 為非負;如果 (index - 2) 處的 char 值屬於高低理項範圍,則返回該代理項對的增補程式碼點值。如果 index - 1 處的 char 值是未配對的低(高)代理項,則返回代理項值。
index - 應返回的程式碼點之後的索引
IndexOutOfBoundsException - 如果 index 參數小於 1 或大於此字元串的長度。
public int codePointCount(int beginIndex,
int endIndex)
String 的指定文本範圍中的 Unicode 程式碼點數。文本範圍始於指定的 beginIndex,一直到索引 endIndex - 1 處的 char。因此,該文本範圍的長度(用 char 表示)是 endIndex-beginIndex。該文本範圍內每個未配對的代理項計為一個程式碼點。
beginIndex - 文本範圍的第一個 char 的索引。endIndex - 文本範圍的最後一個 char 之後的索引。
IndexOutOfBoundsException - 如果 beginIndex 為負,或 endIndex 大於此 String 的長度,或 beginIndex 大於 endIndex。
public int offsetByCodePoints(int index,
int codePointOffset)
String 中從給定的 index 處偏移 codePointOffset 個程式碼點的索引。文本範圍內由 index 和 codePointOffset 給定的未配對代理項各計為一個程式碼點。
index - 要偏移的索引codePointOffset - 程式碼點中的偏移量
String 的索引
IndexOutOfBoundsException - 如果 index 為負或大於此 String 的長度;或者 codePointOffset 為正,且以 index 開頭子字元串的程式碼點比 codePointOffset 少;如果 codePointOffset 為負,且 index 前面子字元串的程式碼點比 codePointOffset 的絕對值少。
public void getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
要複製的第一個字元位於索引 srcBegin 處;要複製的最後一個字元位於索引 srcEnd-1 處(因此要複製的字元總數是 srcEnd-srcBegin)。要複製到 dst 子陣列的字元從索引 dstBegin 處開始,並結束於索引:
dstbegin + (srcEnd-srcBegin) - 1
srcBegin - 字元串中要複製的第一個字元的索引。srcEnd - 字元串中要複製的最後一個字元之後的索引。dst - 目標陣列。dstBegin - 目標陣列中的起始偏移量。
IndexOutOfBoundsException - 如果下列任何一項為 true:
srcBegin 為負。
srcBegin 大於 srcEnd
srcEnd 大於此字元串的長度
dstBegin 為負
dstBegin+(srcEnd-srcBegin) 大於 dst.length
@Deprecated
public void getBytes(int srcBegin,
int srcEnd,
byte[] dst,
int dstBegin)
getBytes() 方法,該方法使用平臺的預設字元集。
要複製的第一個字元位於索引 srcBegin 處;要複製的最後一個字元位於索引 srcEnd-1 處。要複製的字元總數為 srcEnd-srcBegin。將轉換為 byte 的字元複製到 dst 的子陣列中,從索引 dstBegin 處開始,並結束於索引:
dstbegin + (srcEnd-srcBegin) - 1
srcBegin - 字元串中要複製的第一個字元的索引srcEnd - 字元串中要複製的最後一個字元之後的索引dst - 目標陣列dstBegin - 目標陣列中的起始偏移量
IndexOutOfBoundsException - 如果下列任何一項為 true:
srcBegin 為負
srcBegin 大於 srcEnd
srcEnd 大於此 String 的長度
dstBegin 為負
dstBegin+(srcEnd-srcBegin) 大於 dst.length
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException
String 編碼為 byte 序列,並將結果存儲到一個新的 byte 陣列中。
當此字元串不能使用給定的字元集編碼時,此方法的行為沒有指定。如果需要對編碼過程進行更多控制,則應該使用 CharsetEncoder 類別。
charsetName - 受支持的 charset 名稱
UnsupportedEncodingException - 如果指定的字元集不受支持public byte[] getBytes(Charset charset)
String 編碼到 byte 序列,並將結果存儲到新的 byte 陣列。
此方法總是使用此字元集的預設替代 byte 陣列替代錯誤輸入和不可映射字元序列。如果需要對編碼過程進行更多控制,則應該使用 CharsetEncoder 類別。
charset - 用於編碼 String 的 Charset
public byte[] getBytes()
String 編碼為 byte 序列,並將結果存儲到一個新的 byte 陣列中。
當此字元串不能使用預設的字元集編碼時,此方法的行為沒有指定。如果需要對編碼過程進行更多控制,則應該使用 CharsetEncoder 類別。
public boolean equals(Object anObject)
null,並且是與此物件表示相同字元序列的 String 物件時,結果才為 true。
Object 中的 equalsanObject - 與此 String 進行比較的物件。
String 與此 String 相等,則返回 true;否則返回 false。compareTo(String),
equalsIgnoreCase(String)public boolean contentEquals(StringBuffer sb)
StringBuffer 比較。當且僅當此 String 與指定 StringBuffer 表示相同的字元序列時,結果才為 true。
sb - 要與此 String 比較的 StringBuffer。
String 與指定 StringBuffer 表示相同的字元序列,則返回 true;否則返回 false。public boolean contentEquals(CharSequence cs)
CharSequence 比較。當且僅當此 String 與指定序列表示相同的 char 值序列時,結果才為 true。
cs - 要與此 String 比較的序列
String 與指定序列表示相同的 char 值序列,則返回 true;否則返回 false。public boolean equalsIgnoreCase(String anotherString)
String 與另一個 String 比較,不考慮大小寫。如果兩個字元串的長度相同,並且其中的相應字元都相等(忽略大小寫),則認為這兩個字元串是相等的。
在忽略大小寫的情況下,如果下列至少一項為 true,則認為 c1 和 c2 這兩個字元相同。
== 運算符進行比較)。
Character.toUpperCase(char) 產生相同的結果。
Character.toLowerCase(char) 產生相同的結果。
anotherString - 與此 String 進行比較的 String。
null,且這兩個 String 相等(忽略大小寫),則返回 true;否則返回 false。equals(Object)public int compareTo(String anotherString)
String 物件表示的字元序列與參數字元串所表示的字元序列進行比較。如果按字典順序此 String 物件位於參數字元串之前,則比較結果為一個負整數。如果按字典順序此 String 物件位於參數字元串之後,則比較結果為一個正整數。如果這兩個字元串相等,則結果為 0;compareTo 只在方法 equals(Object) 返回 true 時才返回 0。
這是字典排序的定義。如果這兩個字元串不同,那麼它們要麼在某個索引處的字元不同(該索引對二者均為有效索引),要麼長度不同,或者同時具備這兩種情況。如果它們在一個或多個索引位置上的字元不同,假設 k 是這類別索引的最小值;則在位置 k 上具有較小值的那個字元串(使用 < 運算符確定),其字典順序在其他字元串之前。在這種情況下,compareTo 返回這兩個字元串在位置 k 處兩個char 值的差,即值:
如果沒有字元不同的索引位置,則較短字元串的字典順序在較長字元串之前。在這種情況下,this.charAt(k)-anotherString.charAt(k)
compareTo 返回這兩個字元串長度的差,即值:
this.length()-anotherString.length()
Comparable<String> 中的 compareToanotherString - 要比較的 String。
0;如果此字元串按字典順序小於字元串參數,則返回一個小於 0 的值;如果此字元串按字典順序大於字元串參數,則返回一個大於 0 的值。public int compareToIgnoreCase(String str)
compareTo 所得符號相同,規範化字元串的大小寫差異已通過對每個字元調用 Character.toLowerCase(Character.toUpperCase(character)) 消除。
注意,此方法不 考慮語言環境,因此可能導致在某些語言環境中的排序效果不理想。java.text 套件提供 Collators 完成與語言環境有關的排序。
str - 要比較的 String。
Collator.compare(String, String)
public boolean regionMatches(int toffset,
String other,
int ooffset,
int len)
將此 String 物件的一個子字元串與參數 other 的一個子字元串進行比較。如果這兩個子字元串表示相同的字元序列,則結果為 true。要比較的此 String 物件的子字元串從索引 toffset 處開始,長度為 len。要比較的 other 的子字元串從索引 ooffset 處開始,長度為 len。當且僅當下列至少一項為 true 時,結果才為 false :
toffset - 字元串中子區域的起始偏移量。other - 字元串參數。ooffset - 字元串參數中子區域的起始偏移量。len - 要比較的字元數。
true;否則返回 false。
public boolean regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
將此 String 物件的子字元串與參數 other 的子字元串進行比較。如果這兩個子字元串表示相同的字元序列,則結果為 true,當且僅當 ignoreCase 為 true 時忽略大小寫。要比較的此 String 物件的子字元串從索引 toffset 處開始,長度為 len。要比較的 other 的子字元串從索引 ooffset 處開始,長度為 len。當且僅當下列至少一項為 true 時,結果才為 false:
this.charAt(toffset+k) != other.charAt(ooffset+k)
Character.toLowerCase(this.charAt(toffset+k)) !=
Character.toLowerCase(other.charAt(ooffset+k))
Character.toUpperCase(this.charAt(toffset+k)) !=
Character.toUpperCase(other.charAt(ooffset+k))
ignoreCase - 如果為 true,則比較字元時忽略大小寫。toffset - 此字元串中子區域的起始偏移量。other - 字元串參數。toffset - 字元串參數中子區域的起始偏移量。len - 要比較的字元數。
true;否則返回 false。是否完全比對或考慮大小寫取決於 ignoreCase 參數。
public boolean startsWith(String prefix,
int toffset)
prefix - 前綴。toffset - 在此字元串中開始尋找的位置。
toffset 處開始的子字元串前綴,則返回 true;否則返回 false。如果 toffset 為負或大於此 String 物件的長度,則結果為 false;否則結果與以下表達式的結果相同:
this.substring(toffset).startsWith(prefix)
public boolean startsWith(String prefix)
prefix - 前綴。
true;否則返回 false。還要注意,如果參數是空字元串,或者等於此 String 物件(用 equals(Object) 方法確定),則返回 true。public boolean endsWith(String suffix)
suffix - 後綴。
true;否則返回 false。注意,如果參數是空字元串,或者等於此 String 物件(用 equals(Object) 方法確定),則結果為 true。public int hashCode()
String 物件的雜湊碼根據以下公式計算:
使用s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
int 演算法,這裡 s[i] 是字元串的第 i 個字元,n 是字元串的長度,^ 表示求冪。(空字元串的雜湊值為 0。)
Object 中的 hashCodeObject.equals(java.lang.Object),
Hashtablepublic int indexOf(int ch)
String 物件表示的字元序列中出現值為 ch 的字元,則返回第一次出現該字元的索引(以 Unicode 程式碼單元表示)。對於 0 到 0xFFFF(包括 0 和 0xFFFF)範圍內的 ch 的值,返回值是
為 true 的最小 k 值。對於其他this.charAt(k) == ch
ch 值,返回值是
為 true 最小 k 值。無論哪種情況,如果此字元串中沒有這樣的字元,則返回this.codePointAt(k) == ch
-1。
ch - 一個字元(Unicode 程式碼點)。
-1。
public int indexOf(int ch,
int fromIndex)
在此 String 物件表示的字元序列中,如果帶有值 ch 的字元的索引不小於 fromIndex,則返回第一次出現該值的索引。對於 0 到 0xFFFF(包括 0 和 0xFFFF)範圍內的 ch 值,返回值是
為 true 的最小 k 值。對於其他(this.charAt(k) == ch) && (k >= fromIndex)
ch 值,返回值是
為 true 的最小 k 值。無論哪種情況,如果此字元串中(this.codePointAt(k) == ch) && (k >= fromIndex)
fromIndex 或之後的位置沒有這樣的字元出現,則返回 -1。
fromIndex 的值沒有限制。如果它為負,則與它為 0 的效果同樣:將搜尋整個字元串。如果它大於此字元串的長度,則與它等於此字元串長度的效果相同:返回 -1。
所有索引都在 char 值中指定(Unicode 程式碼單元)。
ch - 一個字元(Unicode 程式碼點)。fromIndex - 開始搜尋的索引。
fromIndex 的字元的索引;如果未出現該字元,則返回 -1。public int lastIndexOf(int ch)
ch 的值,返回的索引(Unicode 程式碼單元)是
為 true 最大 k 值。對於其他this.charAt(k) == ch
ch 值,返回值是
為 true 的最大 k 值。無論哪種情況,如果此字元串中沒有這樣的字元出現,則返回this.codePointAt(k) == ch
-1。從最後一個字元開始反向搜尋此 String。
ch - 一個字元(Unicode 程式碼點)。
-1。
public int lastIndexOf(int ch,
int fromIndex)
ch 值,返回的索引是
為 true 的最大 k 值。對於(this.charAt(k) == ch) && (k <= fromIndex)
ch 的其他值,返回值是
為 true 的最大 k 值。無論哪種情況,如果此字元串中(this.codePointAt(k) == ch) && (k <= fromIndex)
fromIndex 或之前的位置沒有這樣的字元出現,則返回 -1。
所有的索引都以 char 值指定(Unicode 程式碼單元)。
ch - 一個字元(Unicode 程式碼點)。fromIndex - 開始搜尋的索引。fromIndex 的值沒有限制。如果它大於等於此字元串的長度,則與它小於此字元串長度減 1 的效果相同:將搜尋整個字元串。如果它為負,則與它為 -1 的效果相同:返回 -1。
fromIndex)中最後一次出現該字元的索引;如果在該點之前未出現該字元,則返回 -1。public int indexOf(String str)
為this.startsWith(str, k)
true 的最小 k 值。
str - 任意字元串。
-1。
public int indexOf(String str,
int fromIndex)
k >= Math.min(fromIndex, this.length()) && this.startsWith(str, k)
str - 要搜尋的子字元串。fromIndex - 開始搜尋的索引位置。
public int lastIndexOf(String str)
this.length() 處。返回的索引是
為 true 的最大 k 值。this.startsWith(str, k)
str - 要搜尋的子字元串。
-1。
public int lastIndexOf(String str,
int fromIndex)
k <= Math.min(fromIndex,this.length()) && this.startsWith(str, k)
str - 要搜尋的子字元串。fromIndex - 開始搜尋的索引位置。
public String substring(int beginIndex)
範例:
"unhappy".substring(2) returns "happy" "Harbison".substring(3) returns "bison" "emptiness".substring(9) returns "" (an empty string)
beginIndex - 起始索引(包括)。
IndexOutOfBoundsException - 如果 beginIndex 為負或大於此 String 物件的長度。
public String substring(int beginIndex,
int endIndex)
beginIndex 處開始,直到索引 endIndex - 1 處的字元。因此,該子字元串的長度為 endIndex-beginIndex。
範例:
"hamburger".substring(4, 8) returns "urge" "smiles".substring(1, 5) returns "mile"
beginIndex - 起始索引(包括)。endIndex - 結束索引(不包括)。
IndexOutOfBoundsException - 如果 beginIndex 為負,或 endIndex 大於此 String 物件的長度,或 beginIndex 大於 endIndex。
public CharSequence subSequence(int beginIndex,
int endIndex)
此方法這種形式的調用:
與以下調用的行為完全相同:str.subSequence(begin, end)
定義此方法使 String 類別能夠實作str.substring(begin, end)
CharSequence 介面。
CharSequence 中的 subSequencebeginIndex - 起始索引(包括)。endIndex - 結束索引(不包括)。
IndexOutOfBoundsException - 如果 beginIndex 或 endIndex 為負,如果 endIndex 大於 length() 或 beginIndex 大於 startIndexpublic String concat(String str)
如果參數字元串的長度為 0,則返回此 String 物件。否則,創建一個新的 String 物件,用來表示由此 String 物件表示的字元序列和參數字元串表示的字元序列連接而成的字元序列。
範例:
"cares".concat("s") returns "caress"
"to".concat("get").concat("her") returns "together"
str - 連接到此 String 結尾的 String。
public String replace(char oldChar,
char newChar)
newChar 替換此字元串中出現的所有 oldChar 得到的。
如果 oldChar 在此 String 物件表示的字元序列中沒有出現,則返回對此 String 物件的參考。否則,創建一個新的 String 物件,它所表示的字元序列除了所有的 oldChar 都被替換為 newChar 之外,與此 String 物件表示的字元序列相同。
範例:
"mesquite in your cellar".replace('e', 'o')
returns "mosquito in your collar"
"the war of baronets".replace('r', 'y')
returns "the way of bayonets"
"sparring with a purple porpoise".replace('p', 't')
returns "starring with a turtle tortoise"
"JonL".replace('q', 'x') returns "JonL" (no change)
oldChar - 原字元。newChar - 新字元。
oldChar 替代為 newChar。public boolean matches(String regex)
調用此方法的 str.matches(regex) 形式與以下表達式產生的結果完全相同:
Pattern.matches(regex, str)
regex - 用來比對此字元串的正則表達式
PatternSyntaxException - 如果正則表達式的語法無效Patternpublic boolean contains(CharSequence s)
s - 要搜尋的序列
s,則返回 true,否則返回 false
NullPointerException - 如果 s 為 null
public String replaceFirst(String regex,
String replacement)
調用此方法的 str.replaceFirst(regex, repl) 形式與以下表達式產生的結果完全相同:
Pattern.compile(regex).matcher(str).replaceFirst(repl)
注意,在替代字元串中使用反斜槓 (\) 和美元符號 ($) 與將其視為文字值替代字元串所得的結果可能不同;請參閱 Matcher.replaceFirst(java.lang.String)。如有需要,可使用 Matcher.quoteReplacement(java.lang.String) 取消這些字元的特殊含義。
regex - 用來比對此字元串的正則表達式replacement - 用來替換第一個比對項的字元串
PatternSyntaxException - 如果正則表達式的語法無效Pattern
public String replaceAll(String regex,
String replacement)
調用此方法的 str.replaceAll(regex, repl) 形式與以下表達式產生的結果完全相同:
Pattern.compile(regex).matcher(str).replaceAll(repl)
注意,在替代字元串中使用反斜槓 (\) 和美元符號 ($) 與將其視為文字值替代字元串所得的結果可能不同;請參閱 Matcher.replaceAll。如有需要,可使用 Matcher.quoteReplacement(java.lang.String) 取消這些字元的特殊含義。
regex - 用來比對此字元串的正則表達式replacement - 用來替換每個比對項的字元串
PatternSyntaxException - 如果正則表達式的語法無效Pattern
public String replace(CharSequence target,
CharSequence replacement)
target - 要被替換的 char 值序列replacement - char 值的替換序列
NullPointerException - 如果 target 或 replacement 為 null。
public String[] split(String regex,
int limit)
此方法返回的陣列包含此字元串的子字元串,每個子字元串都由另一個比對給定表達式的子字元串終止,或者由此字元串末尾終止。陣列中的子字元串按它們在此字元串中出現的順序排列。如果表達式不比對輸入的任何部分,那麼所得陣列只具有一個元素,即此字元串。
limit 參數控制網要應用的次數,因此影響所得陣列的長度。如果該限制 n 大於 0,則網要將被最多應用 n - 1 次,陣列的長度將不會大於 n,而且陣列的最後一項將包含所有超出最後比對的定界符的輸入。如果 n 為非正,那麼網要將被應用盡可能多的次數,而且陣列可以是任何長度。如果 n 為 0,那麼網要將被應用盡可能多的次數,陣列可以是任何長度,並且結尾空字元串將被丟棄。
例如,字元串 "boo:and:foo" 使用這些參數可產生以下結果:
Regex Limit 結果 : 2 { "boo", "and:foo" } : 5 { "boo", "and", "foo" } : -2 { "boo", "and", "foo" } o 5 { "b", "", ":and:f", "", "" } o -2 { "b", "", ":and:f", "", "" } o 0 { "b", "", ":and:f" }
調用此方法的 str.split(regex, n) 形式與以下表達式產生的結果完全相同:
Pattern.compile(regex).split(str, n)
regex - 定界正則表達式limit - 結果閾值,如上所述
PatternSyntaxException - 如果正則表達式的語法無效Patternpublic String[] split(String regex)
該方法的作用就像是使用給定的表達式和限制參數 0 來調用兩參數 split 方法。因此,所得陣列中不包括結尾空字元串。
例如,字元串 "boo:and:foo" 使用這些表達式可產生以下結果:
Regex 結果 : { "boo", "and", "foo" } o { "b", "", ":and:f" }
regex - 定界正則表達式
PatternSyntaxException - 如果正則表達式的語法無效Patternpublic String toLowerCase(Locale locale)
Locale 的規則將此 String 中的所有字元都轉換為小寫。大小寫映射關係基於 Character 類別指定的 Unicode 標準版。由於大小寫映射關係並不總是 1:1 的字元映射關係,因此所得 String 的長度可能不同於原 String。
下表中給出了幾個小寫映射關係的範例:
| 語言環境的程式碼 | 大寫字母 | 小寫字母 | 描述 |
|---|---|---|---|
| tr (Turkish) | \u0130 | \u0069 | 大寫字母 I,上面有點 -> 小寫字母 i |
| tr (Turkish) | \u0049 | \u0131 | 大寫字母 I -> 小寫字母 i,無點 |
| (all) | French Fries | french fries | 將字元串中的所有字元都小寫 |
| (all) | 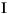 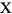
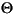 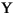
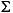 |
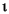 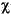
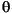 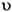
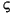 |
將字元串中的所有字元都小寫 |
locale - 使用此語言環境的大小寫轉換規則
String。toLowerCase(),
toUpperCase(),
toUpperCase(Locale)public String toLowerCase()
String 中的所有字元都轉換為小寫。這等效於調用 toLowerCase(Locale.getDefault())。
註: 此方法與語言環境有關,如果用於應獨立於語言環境解釋的字元串,則可能產生不可預料的結果。
範例有程式語言標識符、協議鍵、HTML 標記。
例如,"TITLE".toLowerCase() 在 Turkish(土耳其語)語言環境中返回 "t?tle",其中「?」是 LATIN SMALL LETTER DOTLESS I 字元。
對於與語言環境有關的字元,要獲得正確的結果,請使用 toLowerCase(Locale.ENGLISH)。
String。toLowerCase(Locale)public String toUpperCase(Locale locale)
Locale 的規則將此 String 中的所有字元都轉換為大寫。大小寫映射關係基於 Character 類別指定的 Unicode 標準版。由於大小寫映射關係並不總是 1:1 的字元映射關係,因此所得 String 的長度可能不同於原 String。
下表中給出了幾個與語言環境有關和 1:M 大小寫映射關係的一些範例。
| 語言環境的程式碼 | 小寫 | 大寫 | 描述 |
|---|---|---|---|
| tr (Turkish) | \u0069 | \u0130 | 小寫字母 i -> 大寫字母 I,上面有點 |
| tr (Turkish) | \u0131 | \u0049 | 小寫字母 i,無點 -> 大寫字母 I |
| (all) | \u00df | \u0053 \u0053 | 小寫字母 sharp s -> 兩個字母:SS |
| (all) | Fahrvergnügen | FAHRVERGNÜN |
locale - 使用此語言環境的大小寫轉換規則
String。toUpperCase(),
toLowerCase(),
toLowerCase(Locale)public String toUpperCase()
String 中的所有字元都轉換為大寫。此方法等效於 toUpperCase(Locale.getDefault())。
註: 此方法與語言環境有關,如果用於應獨立於語言環境解釋的字元串,則可能產生不可預料的結果。
範例有程式語言標識符、協議鍵、HTML 標記。
例如,"title".toUpperCase() 在 Turkish(土耳其語)語言環境中返回 "T?TLE",其中「?」是 LATIN CAPITAL LETTER I WITH DOT ABOVE 字元。
對於與語言環境有關的字元,要獲得正確的結果,請使用 toUpperCase(Locale.ENGLISH)。
String。toUpperCase(Locale)public String trim()
如果此 String 物件表示一個空字元序列,或者此 String 物件表示的字元序列的第一個和最後一個字元的程式碼都大於 '\u0020'(空格字元),則返回對此 String 物件的參考。
否則,若字元串中沒有程式碼大於 '\u0020' 的字元,則創建並返回一個表示空字元串的新 String 物件。
否則,假定 k 為字元串中程式碼大於 '\u0020' 的第一個字元的索引,m 為字元串中程式碼大於 '\u0020' 的最後一個字元的索引。創建一個新的 String 物件,它表示此字元串中從索引 k 處的字元開始,到索引 m 處的字元結束的子字元串,即 this.substring(k, m+1) 的結果。
此方法可用於截去字元串開頭和末尾的空白(如上所述)。
public String toString()
CharSequence 中的 toStringObject 中的 toStringpublic char[] toCharArray()
public static String format(String format,
Object... args)
始終使用 Locale.getDefault() 返回的語言環境。
format - 格式字元串args - 格式字元串中由格式說明符參考的參數。如果還有格式說明符以外的參數,則忽略這些額外的參數。參數的數目是可變的,可以為 0。參數的最大數目受 Java Virtual Machine Specification 所定義的 Java 陣列最大維度的限制。有關 null 參數的行為依賴於轉換。
IllegalFormatException - 如果格式字元串中包含非法語法、與給定的參數不相容的格式說明符,格式字元串給定的參數不夠,或者存在其他非法條件。有關所有可能的格式化錯誤的規範,請參閱 formatter 類別規範的詳細資訊 一節。
NullPointerException - 如果 format 為 nullFormatter
public static String format(Locale l,
String format,
Object... args)
l - 格式化過程中要應用的語言環境。如果 l 為 null,則不進行本地化。format - 格式字元串args - 格式字元串中由格式說明符參考的參數。如果還有格式說明符以外的參數,則忽略這些額外的參數。參數的數目是可變的,可以為 0。參數的最大數目受 Java Virtual Machine Specification 所定義的 Java 陣列最大維度的限制。有關 null 參數的行為依賴於轉換。
IllegalFormatException - 如果格式字元串中包含非法語法、與給定參數不相容的格式說明符,格式字元串給定的參數不夠,或存在其他非法條件。有關所有可能的格式化錯誤的規範,請參閱 formatter 類別規範的詳細資訊 一節。
NullPointerException - 如果 format 為 nullFormatterpublic static String valueOf(Object obj)
Object 參數的字元串表示形式。
obj - 一個 Object。
null,則字元串等於 "null";否則,返回 obj.toString() 的值。Object.toString()public static String valueOf(char[] data)
char 陣列參數的字元串表示形式。字元陣列的內容已被複製,後續修改不會影響新創建的字元串。
data - char 陣列。
public static String valueOf(char[] data,
int offset,
int count)
char 陣列參數的特定子陣列的字元串表示形式。
offset 參數是子陣列的第一個字元的索引。count 參數指定子陣列的長度。字元陣列的內容已被複製,後續修改不會影響新創建的字元串。
data - 字元陣列。offset - String 值的初始偏移量。count - String 值的長度。
IndexOutOfBoundsException - 如果 offset 為負,count 為負,或者 offset+count 大於 data.length。
public static String copyValueOf(char[] data,
int offset,
int count)
data - 字元陣列。offset - 子陣列的初始偏移量。count - 子陣列的長度。
String,它包含字元陣列的指定子陣列的字元。public static String copyValueOf(char[] data)
data - 字元陣列。
String,它包含字元陣列的字元。public static String valueOf(boolean b)
boolean 參數的字元串表示形式。
b - 一個 boolean。
true,則返回一個等於 "true" 的字元串;否則,返回一個等於 "false" 的字元串。public static String valueOf(char c)
char 參數的字元串表示形式。
c - 一個 char。
1 的字元串,它包含參數 c 的單個字元。public static String valueOf(int i)
int 參數的字元串表示形式。
該表示形式恰好是單參數的 Integer.toString 方法返回的結果。
i - 一個 int。
int 參數的字元串表示形式。Integer.toString(int, int)public static String valueOf(long l)
long 參數的字元串表示形式。
該表示形式恰好是單參數的 Long.toString 方法返回的結果。
l - 一個 long。
long 參數的字元串表示形式。Long.toString(long)public static String valueOf(float f)
float 參數的字元串表示形式。
該表示形式恰好是單參數的 Float.toString 方法返回的結果。
f - 一個 float。
float 參數的字元串表示形式。Float.toString(float)public static String valueOf(double d)
double 參數的字元串表示形式。
該表示形式恰好是單參數的 Double.toString 方法返回的結果。
d - 一個 double。
double 參數的字元串表示形式。Double.toString(double)public String intern()
一個初始為空的字元串池,它由類別 String 私有地維護。
當調用 intern 方法時,如果池已經包含一個等於此 String 物件的字元串(用 equals(Object) 方法確定),則返回池中的字元串。否則,將此 String 物件添加到池中,並返回此 String 物件的參考。
它遵循以下規則:對於任意兩個字元串 s 和 t,當且僅當 s.equals(t) 為 true 時,s.intern() == t.intern() 才為 true。
所有文字值字元串和字元串賦值常數表達式都使用 intern 方法進行操作。字元串文字值在 Java Language Specification 的 §3.10.5 定義。
|
JavaTM 2 Platform Standard Ed. 6 |
|||||||||
| 上一個類別 下一個類別 | 框架 無框架 | |||||||||
| 摘要: 巢狀 | 欄位 | 建構子 | 方法 | 詳細資訊: 欄位 | 建構子 | 方法 | |||||||||
版權所有 2008 Sun Microsystems, Inc. 保留所有權利。請遵守GNU General Public License, version 2 only。